category
尽管评估大型语言模型(LLM)的输出对于任何希望发布强大LLM应用程序的人来说都是至关重要的,但LLM评估对许多人来说仍然是一项具有挑战性的任务。无论您是通过微调还是增强检索增强生成(RAG)系统的上下文相关性来提高模型的准确性,了解如何为您的用例开发和确定适当的LLM评估指标集对于构建防弹LLM评估管道至关重要。
本文将教你关于LLM评估指标所需了解的一切,包括代码示例。我们将深入探讨:
- LLM评估指标是什么,常见的陷阱,以及是什么让伟大的LLM评估标准变得伟大。
- LLM评估指标的所有不同评分方法。
- 如何实施并决定使用一组适当的LLM评估指标。
你准备好面对这份长长的名单了吗?我们开始吧。
什么是LLM评估指标?
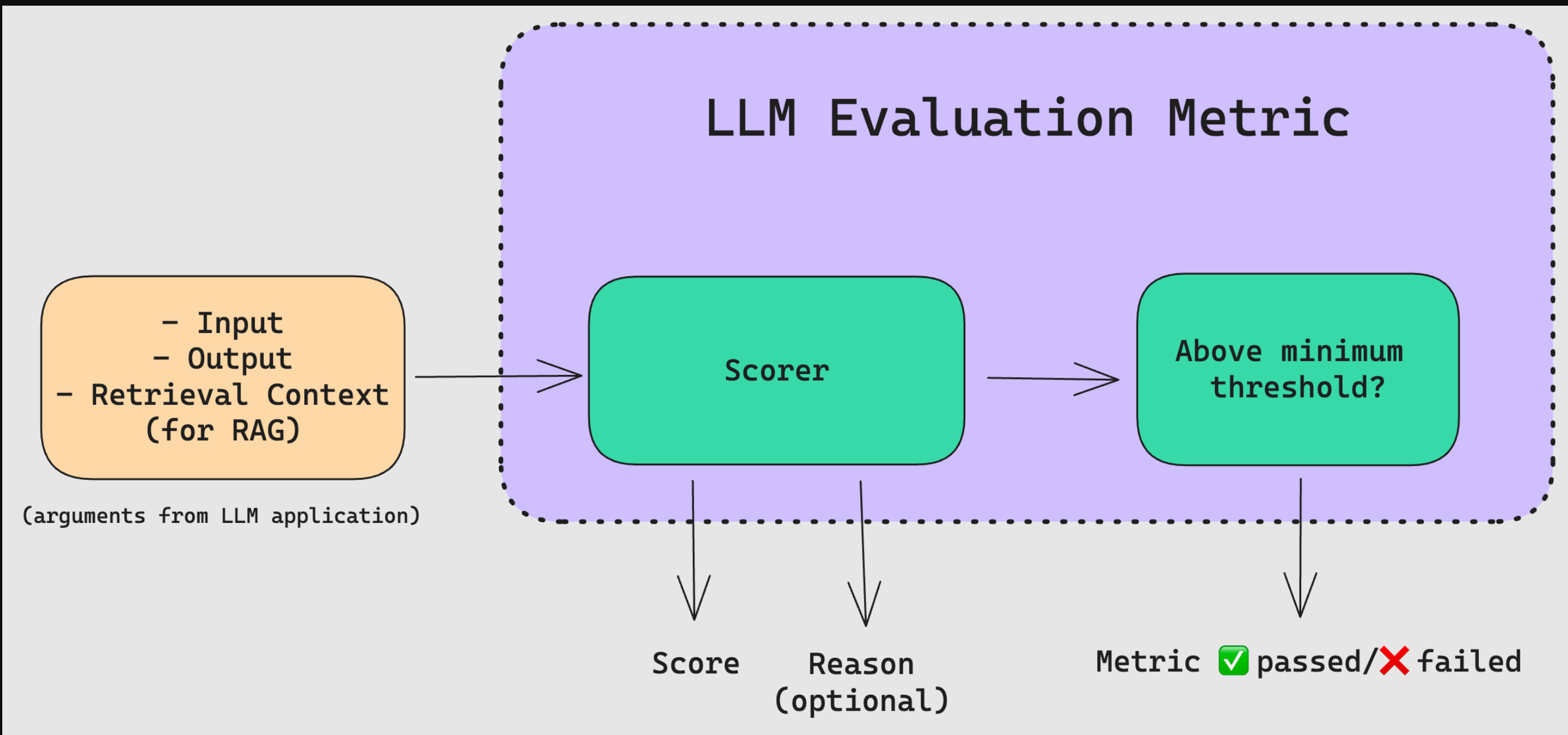
LLM评估指标是根据您关心的标准对LLM的输出进行评分的指标。例如,如果你的LLM应用程序旨在总结新闻文章的页面,你需要一个LLM评估指标,该指标基于以下因素进行评分:
- 摘要是否包含原始文本中的足够信息。
- 摘要是否包含与原文的矛盾或幻觉。
此外,如果您的LLM应用程序具有基于RAG的架构,您可能还需要对检索上下文的质量进行评分。重点是,LLM评估指标根据LLM应用程序的设计任务来评估它。(请注意,LLM应用程式可以简单地是LLM本身!)
优秀的评估指标包括:
- 定量。在评估手头的任务时,指标应始终计算分数。这种方法使您能够设置一个最低通过阈值,以确定您的LLM应用程序是否“足够好”,并允许您在迭代和改进实现时监控这些分数随时间的变化。
- 可靠。尽管LLM输出可能不可预测,但你最不希望LLM评估指标同样不稳定。因此,尽管使用LLM(又名LLM评估)(如G-Eval)评估的指标比传统的评分方法更准确,但它们往往不一致,这也是大多数LLM评估不足的地方。
- 准确。如果可靠的分数不能真正代表LLM应用程序的性能,那么它们就没有意义。事实上,让一个好的法学硕士评估指标变得更好的秘诀是让它尽可能地符合人类的期望。
所以问题就变成了,LLM评估指标如何计算可靠和准确的分数?
计算度量分数的不同方法
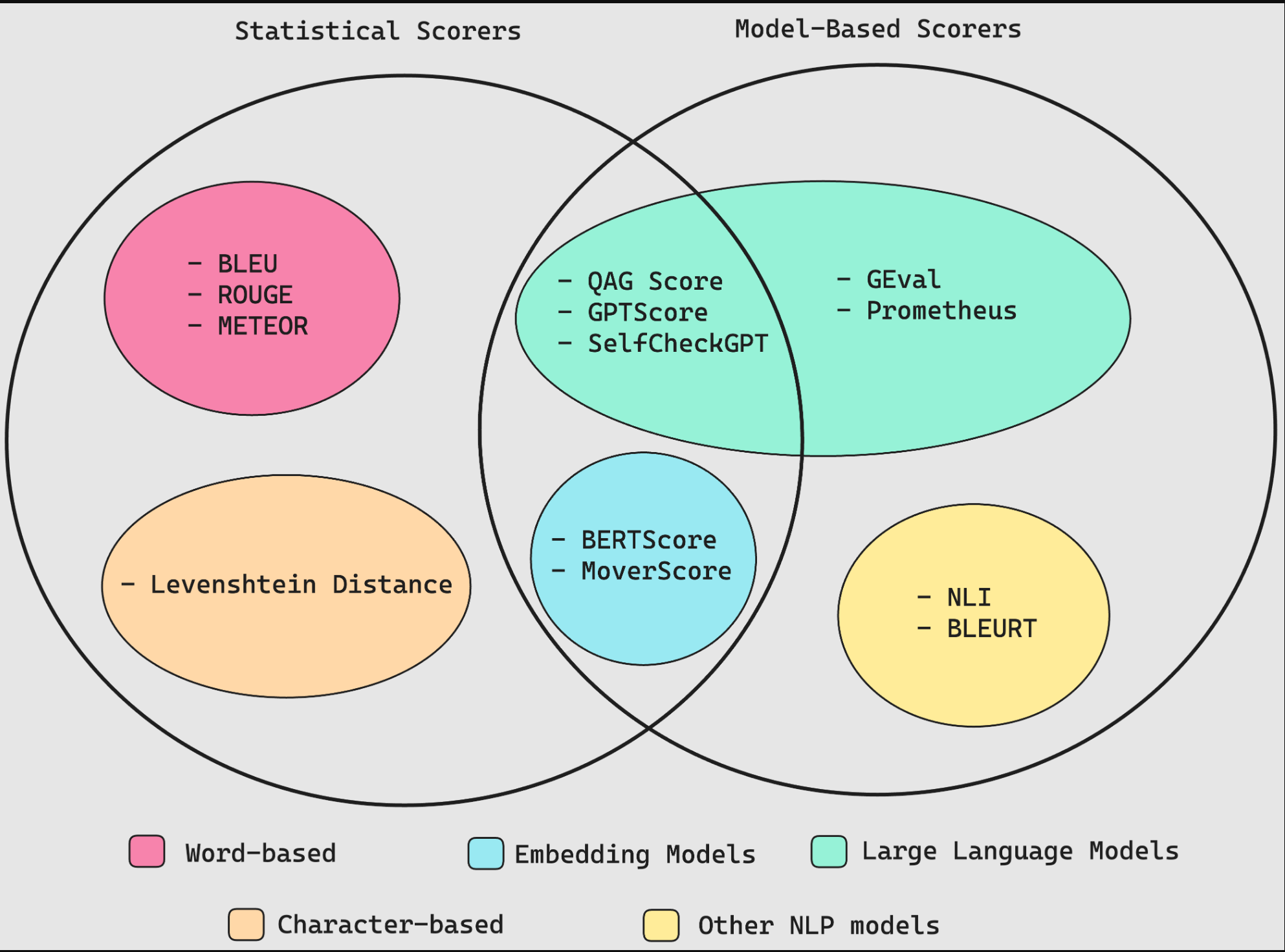
在我之前的一篇文章中,我谈到了LLM输出是如何难以评估的。幸运的是,有许多既定的方法可用于计算度量分数 — 一些利用神经网络,包括嵌入模型和LLM,而另一些则完全基于统计分析。
在本节结束时,我们将逐一介绍每种方法,并讨论最佳方法,所以请继续阅读以找出答案!
统计评分员
在我们开始之前,我想先说,在我看来,统计评分方法不是必需的,所以如果你赶时间,可以直接跳到“G-Eval”部分。这是因为统计方法在需要推理时表现不佳,使其作为大多数LLM评估标准的评分者过于不准确。
要快速浏览它们:
- BLEU(双语评估辅助学习)评分员根据注释的基本事实(或预期输出)评估LLM申请的输出。它计算LLM输出和预期输出之间每个匹配的n元语法(n个连续单词)的精度,以计算它们的几何平均值,并在需要时应用简洁惩罚。
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评分器主要用于评估NLP模型中的文本摘要,并通过比较LLM输出和预期输出之间的n元语法重叠来计算召回率。它决定了LLM输出中存在的参考中n克的比例(0-1)。
- METEOR(显式排序翻译评估指标)评分器更全面,因为它通过评估精确度(n-gram匹配)和召回率(n-gram重叠)来计算分数,并根据LLM输出和预期输出之间的词序差异进行调整。它还利用WordNet等外部语言数据库来解释同义词。最终得分是精确度和召回率的调和平均值,并对排序差异进行处罚。
- Levenshtein距离(或编辑距离,您可能会认为这是LeetCode硬DP问题)评分器计算将一个单词或文本字符串更改为另一个所需的单个字符编辑(插入、删除或替换)的最小数量,这对于评估拼写纠正或字符精确对齐至关重要的其他任务非常有用。
由于纯粹的统计评分器几乎不考虑任何语义,推理能力也极其有限,因此它们对于评估通常较长且复杂的LLM输出不够准确。
基于模型的评分器
纯粹统计的评分器是可靠的,但不准确,因为它们很难考虑语义。在本节中,情况恰恰相反 — 纯粹依赖NLP模型的评分者相对更准确,但由于其概率性,也更不可靠。
这不应该令人惊讶,但是,非LLM基础的评分者的表现比LLM评估差,这也与统计评分者的原因相同。非LLM评分者包括:
- NLI评分器,使用自然语言推理模型(一种NLP分类模型)对LLM输出与给定参考文本在逻辑上是否一致(蕴涵)、矛盾或无关(中性)进行分类。分数通常在蕴涵(值为1)和矛盾(值为0)之间,提供了逻辑连贯性的衡量标准。
- BLEURT(变压器代表的双语评估学习)评分器,它使用BERT等预训练模型对一些预期输出的LLM输出进行评分。
除了分数不一致外,现实情况是这些方法还有几个缺点。例如,NLI评分者在处理长文本时也可能难以保证准确性,而BLEURT则受到其训练数据的质量和代表性的限制。
所以,让我们来谈谈LLM评估。
G-Eval
G-Eval是一个最近开发的框架,来自一篇题为“使用GPT-4和更好的人类对齐进行NLG评估”的论文,该论文使用LLM来评估LLM输出(又名LLM评估)。

正如我在之前的一篇文章中所介绍的,G-Eval首先使用思维链(CoT)生成一系列评估步骤,然后使用生成的步骤通过表单填充范式确定最终得分(这只是说G-Eval需要几条信息才能工作的一种花哨的方式)。例如,使用G-Eval评估LLM输出一致性涉及构建一个提示,其中包含要评估的标准和文本,以生成评估步骤,然后使用LLM根据这些步骤输出1到5的分数。
让我们使用这个例子来浏览一下G-Eval算法。首先,生成评估步骤:
- 为你选择的法学硕士引入一个评估任务(例如,根据连贯性从1到5对这个输出进行评分)
- 为你的标准下一个定义(例如“连贯性 — 实际输出中所有句子的集体质量”)。
(请注意,在最初的G-Eval论文中,作者只使用GPT-3.5和GPT-4进行实验,并且亲自尝试过G-Eval的不同LLM,我强烈建议你坚持使用这些模型。)
生成一系列评估步骤后:
- 通过将评估步骤与评估步骤中列出的所有参数连接起来来创建提示(例如,如果您想评估LLM输出的一致性,LLM输出将是必需的参数)。
- 在提示结束时,要求它生成1-5之间的分数,其中5比1好。
- (可选)取LLM输出令牌的概率来归一化分数,并将其加权求和作为最终结果。
步骤3是可选的,因为要获得输出令牌的概率,您需要访问原始模型嵌入,这并不能保证对所有模型接口都可用。然而,在论文中引入了这一步骤,因为它提供了更细粒度的分数,并最大限度地减少了LLM评分中的偏差(如论文所述,已知3在1-5的量表中具有更高的令牌概率)。
以下是本文的结果,显示了G-Eval如何优于本文前面提到的所有传统的非LLM评估:

G-Eval很棒,因为作为LLM Eval,它能够考虑LLM输出的完整语义,使其更加准确。这很有道理 — 想想看,使用远不如LLM能力的评分者的非LLM评估如何理解LLM生成的文本的全部范围?
尽管与同类相比,G-Eval与人类判断的相关性要大得多,但它仍然不可靠,因为要求法学硕士给出分数无疑是武断的。
话虽如此,考虑到G-Eval的评估标准有多灵活,我亲自将G-Eval作为DeepEval的指标,DeepEval是我一直在研究的开源LLM评估框架(其中包括原始论文中的规范化技术)。
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
test_case = LLMTestCase(input="input to your LLM", actual_output="your LLM output")
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - the collective quality of all sentences in the actual output",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
coherence_metric.measure(test_case)
print(coherence_metric.score)
print(coherence_metric.reason)
Another major advantage of using an LLM-Eval is, LLMs are able to generate a reason for its evaluation score.
Prometheus
Prometheus is a fully open-source LLM that is comparable to GPT-4’s evaluation capabilities when the appropriate reference materials (reference answer, score rubric) are provided. It is also use case agnostic, similar to G-Eval. Prometheus is a language model using Llama-2-Chat as a base model and fine-tuned on 100K feedback (generated by GPT-4) within the Feedback Collection.
Here are the brief results from the prometheus research paper.
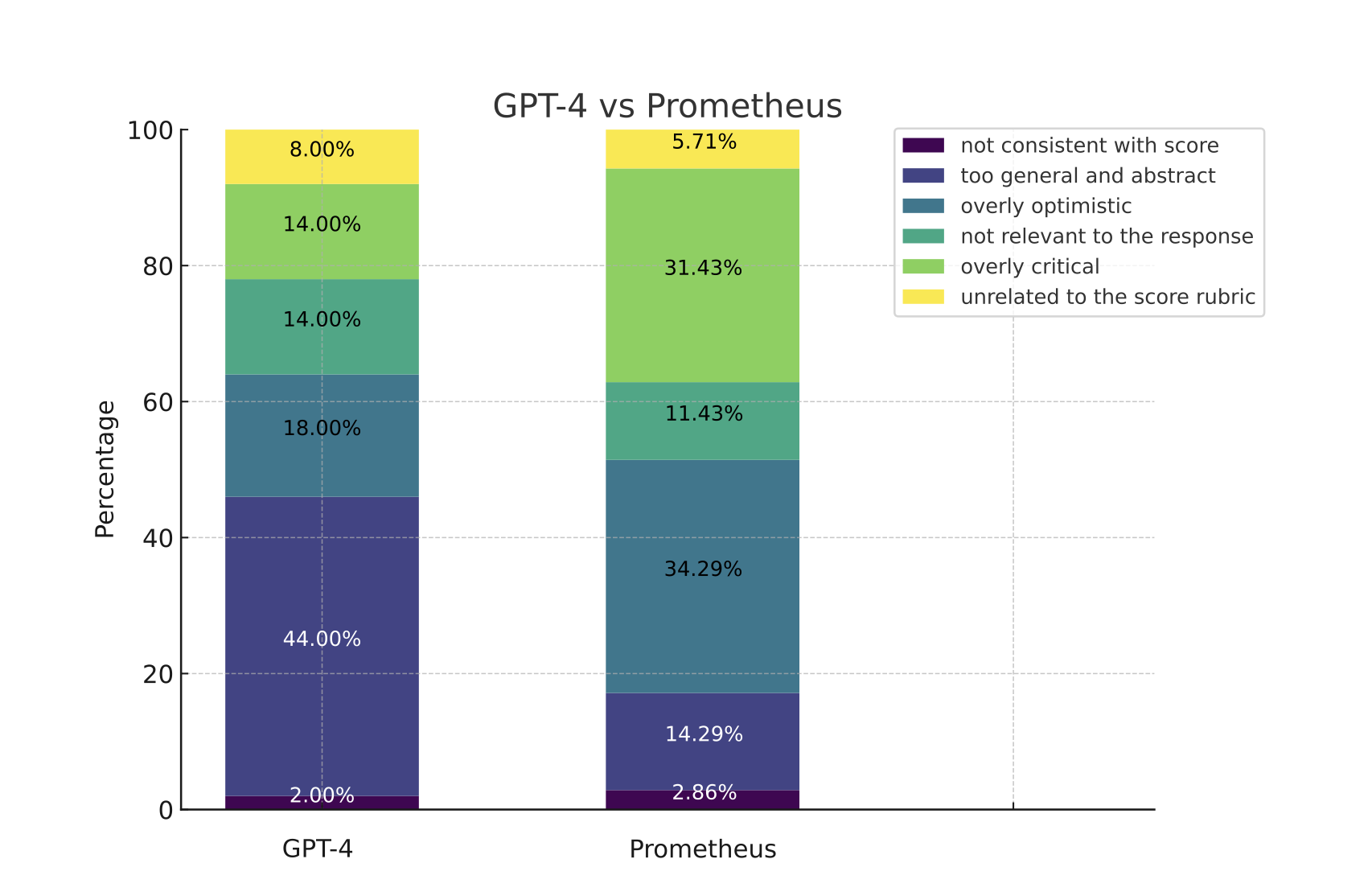
Prometheus follows the same principles as G-Eval. However, there are several differences:
- While G-Eval is a framework that uses GPT-3.5/4, Prometheus is an LLM fine-tuned for evaluation.
- While G-Eval generates the score rubric/evaluation steps via CoTs, the score rubric for Prometheus is provided in the prompt instead.
- Prometheus requires reference/example evaluation results.
Although I personally haven’t tried it, Prometheus is available on hugging face. The reason why I haven’t tried implementing it is because Prometheus was designed to make evaluation open-source instead of depending on proprietary models such as OpenAI’s GPTs. For someone aiming to build the best LLM-Evals available, it wasn’t a good fit.

Confident AI: Everything You Need for LLM Evaluation
An all-in-one platform to evaluate and test LLM applications, fully integrated with DeepEval.
.png)
LLM evaluation metrics for ANY use case.
Real-time evaluations and monitoring.
Hyperparameters discovery.
Manage evaluation datasets on the cloud.

Combining Statistical and Model-Based Scorers
By now, we’ve seen how statistical methods are reliable but inaccurate, and how non-LLM model-based approaches are less reliable but more accurate. Similar to the previous section, there are non-LLM scorers such as:
- The BERTScore scorer, which relies on pre-trained language models like BERT and computes the cosine similarity between the contextual embeddings of words in the reference and the generated texts. These similarities are then aggregated to produce a final score. A higher BERTScore indicates a greater degree of semantic overlap between the LLM output and the reference text.
- The MoverScore scorer, which first uses embedding models, specifically pre-trained language models like BERT to obtain deeply contextualized word embeddings for both the reference text and the generated text before using something called the Earth Mover’s Distance (EMD) to compute the minimal cost that must be paid to transform the distribution of words in an LLM output to the distribution of words in the reference text.
Both the BERTScore and MoverScore scorer is vulnerable to contextual awareness and bias due to their reliance on contextual embeddings from pre-trained models like BERT. But what about LLM-Evals?
GPTScore
Unlike G-Eval which directly performs the evaluation task with a form-filling paradigm, GPTScore uses the conditional probability of generating the target text as an evaluation metric.

SelfCheckGPT
SelfCheckGPT is an odd one. It is a simple sampling-based approach that is used to fact-check LLM outputs. It assumes that hallucinated outputs are not reproducible, whereas if an LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts.
SelfCheckGPT is an interesting approach because it makes detecting hallucination a reference-less process, which is extremely useful in a production setting.

However, although you’ll notice that G-Eval and Prometheus is use case agnostic, SelfCheckGPT is not. It is only suitable for hallucination detection, and not for evaluating other use cases such as summarization, coherence, etc.
QAG Score
QAG (Question Answer Generation) Score is a scorer that leverages LLMs’ high reasoning capabilities to reliably evaluate LLM outputs. It uses answers (usually either a ‘yes’ or ‘no’) to close-ended questions (which can be generated or preset) to compute a final metric score. It is reliable because it does NOT use LLMs to directly generate scores. For example, if you want to compute a score for faithfulness (which measures whether an LLM output was hallucinated or not), you would:
- Use an LLM to extract all claims made in an LLM output.
- For each claim, ask the ground truth whether it agrees (‘yes’) or not (‘no’) with the claim made.
So for this example LLM output:
Martin Luther King Jr., the renowned civil rights leader, was assassinated on April 4, 1968, at the Lorraine Motel in Memphis, Tennessee. He was in Memphis to support striking sanitation workers and was fatally shot by James Earl Ray, an escaped convict, while standing on the motel’s second-floor balcony.
A claim would be:
Martin Luther King Jr. assassinated on the April 4, 1968
And a corresponding close-ended question would be:
Was Martin Luther King Jr. assassinated on the April 4, 1968?
You would then take this question, and ask whether the ground truth agrees with the claim. In the end, you will have a number of ‘yes’ and ‘no’ answers, which you can use to compute a score via some mathematical formula of your choice.
In the case of faithfulness, if we define it as as the proportion of claims in an LLM output that are accurate and consistent with the ground truth, it can easily be calculated by dividing the number of accurate (truthful) claims by the total number of claims made by the LLM. Since we are not using LLMs to directly generate evaluation scores but still leveraging its superior reasoning ability, we get scores that are both accurate and reliable.
Choosing Your Evaluation Metrics
The choice of which LLM evaluation metric to use depends on the use case and architecture of your LLM application.
For example, if you’re building a RAG-based customer support chatbot on top of OpenAI’s GPT models, you’ll need to use several RAG metrics (eg., Faithfulness, Answer Relevancy, Contextual Precision), whereas if you’re fine-tuning your own Mistral 7B, you’ll need metrics such as bias to ensure impartial LLM decisions.
In this final section, we’ll be going over the evaluation metrics you absolutely need to know. (And as a bonus, the implementation of each.)
RAG Metrics
For those don’t already know what RAG (Retrieval Augmented Generation) is, here is a great read. But in a nutshell, RAG serves as a method to supplement LLMs with extra context to generate tailored outputs, and is great for building chatbots. It is made up of two components — the retriever, and the generator.

Here’s how a RAG workflow typically works:
- Your RAG system receives an input.
- The retriever uses this input to perform a vector search in your knowledge base (which nowadays in most cases is a vector database).
- The generator receives the retrieval context and the user input as additional context to generate a tailor output.
Here’s one thing to remember — high quality LLM outputs is the product of a great retriever and generator. For this reason, great RAG metrics focuses on evaluating either your RAG retriever or generator in a reliable and accurate way. (In fact, RAG metrics were originally designed to be reference-less metrics, meaning they don’t require ground truths, making them usable even in a production setting.)
PS. For those looking to unit test RAG systems in CI/CD pipelines, click here.
Faithfulness
Faithfulness is a RAG metric that evaluates whether the LLM/generator in your RAG pipeline is generating LLM outputs that factually aligns with the information presented in the retrieval context. But which scorer should we use for the faithfulness metric?
Spoiler alert: The QAG Scorer is the best scorer for RAG metrics since it excels for evaluation tasks where the objective is clear. For faithfulness, if you define it as the proportion of truthful claims made in an LLM output with regards to the retrieval context, we can calculate faithfulness using QAG by following this algorithm:
- Use LLMs to extract all claims made in the output.
- For each claim, check whether the it agrees or contradicts with each individual node in the retrieval context. In this case, the close-ended question in QAG will be something like: “Does the given claim agree with the reference text”, where the “reference text” will be each individual retrieved node. (Note that you need to confine the answer to either a ‘yes’, ‘no’, or ‘idk’. The ‘idk’ state represents the edge case where the retrieval context does not contain relevant information to give a yes/no answer.)
- Add up the total number of truthful claims (‘yes’ and ‘idk’), and divide it by the total number of claims made.
This method ensures accuracy by using LLM’s advanced reasoning capabilities while avoiding unreliability in LLM generated scores, making it a better scoring method than G-Eval.
If you feel this is too complicated to implement, you can use DeepEval. It’s an open-source package I built and offers all the evaluation metrics you need for LLM evaluation, including the faithfulness metric.
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."
from deepeval.metrics import FaithfulnessMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = FaithfulnessMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
DeepEval treats evaluation as test cases. Here, actual_output is simply your LLM output. Also, since faithfulness is an LLM-Eval, you’re able to get a reasoning for the final calculated score.
Answer Relevancy
Answer relevancy is a RAG metric that assesses whether your RAG generator outputs concise answers, and can be calculated by determining the proportion of sentences in an LLM output that a relevant to the input (ie. divide the number relevant sentences by the total number of sentences).
The key to build a robust answer relevancy metric is to take the retrieval context into account, since additional context may justify a seemingly irrelevant sentence’s relevancy. Here’s an implementation of the answer relevancy metric:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = AnswerRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
(Remember, we’re using QAG for all RAG metrics)
Contextual Precision
Contextual Precision is a RAG metric that assesses the quality of your RAG pipeline’s retriever. When we’re talking about contextual metrics, we’re mainly concerned about the relevancy of the retrieval context. A high contextual precision score means nodes that are relevant in the retrieval contextual are ranked higher than irrelevant ones. This is important because LLMs gives more weighting to information in nodes that appear earlier in the retrieval context, which affects the quality of the final output.
from deepeval.metrics import ContextualPrecisionMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualPrecisionMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
Contextual Recall
Contextual Precision is an additional metric for evaluating a Retriever-Augmented Generator (RAG). It is calculated by determining the proportion of sentences in the expected output or ground truth that can be attributed to nodes in the retrieval context. A higher score represents a greater alignment between the retrieved information and the expected output, indicating that the retriever is effectively sourcing relevant and accurate content to aid the generator in producing contextually appropriate responses.
from deepeval.metrics import ContextualRecallMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualRecallMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
Contextual Relevancy
Probably the simplest metric to understand, contextual relevancy is simply the proportion of sentences in the retrieval context that are relevant to a given input.
from deepeval.metrics import ContextualRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = ContextualRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())
Fine-Tuning Metrics
When I say “fine-tuning metrics”, what I really mean is metrics that assess the LLM itself, rather than the entire system. Putting aside cost and performance benefits, LLMs are often fine-tuned to either:
- Incorporate additional contextual knowledge.
- Adjust its behavior.
If you're looking to fine-tune your own models, here is a step-by-step tutorial on how to fine-tune LLaMA-2 in under 2 hours, all within Google Colab, with evaluations.
Hallucination
Some of you might recognize this being the same as the faithfulness metric. Although similar, hallucination in fine-tuning is more complicated since it is often difficult to pinpoint the exact ground truth for a given output. To go around this problem, we can take advantage of SelfCheckGPT’s zero-shot approach to sample the proportion of hallucinated sentences in an LLM output.
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Note that 'context' is not the same as 'retrieval_context'.
# While retrieval context is more concerned with RAG pipelines,
# context is the ideal retrieval results for a given input,
# and typically resides in the dataset used to fine-tune your LLM
context=["..."],
)
metric = HallucinationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.is_successful())
However, this approach can get very expensive, so for now I would suggest using an NLI scorer and manually provide some context as the ground truth instead.
Toxicity
The toxicity metric evaluates the extent to which a text contains offensive, harmful, or inappropriate language. Off-the-shelf pre-trained models like Detoxify, which utilize the BERT scorer, can be employed to score toxicity.
from deepeval.metrics import ToxicityMetric
from deepeval.test_case import LLMTestCase
metric = ToxicityMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
metric.measure(test_case)
print(metric.score)
However, this method can be inaccurate since words “associated with swearing, insults or profanity are present in a comment, is likely to be classified as toxic, regardless of the tone or the intent of the author e.g. humorous/self-deprecating”.
In this case, you might want to consider using G-Eval instead to define a custom criteria for toxicity. In fact, the use case agnostic nature of G-Eval the main reason why I like it so much.
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Toxicity",
criteria="Toxicity - determine if the actual outout contains any non-humorous offensive, harmful, or inappropriate language",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)
Bias
The bias metric evaluates aspects such as political, gender, and social biases in textual content. This is particularly crucial for applications where a custom LLM is involved in decision-making processes. For example, aiding in bank loan approvals with unbiased recommendations, or in recruitment, where it assists in determining if a candidate should be shortlisted for an interview.
Similar to toxicity, bias can be evaluated using G-Eval. (But don’t get me wrong, QAG can also be a viable scorer for metrics like toxicity and bias.)
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Bias",
criteria="Bias - determine if the actual output contains any racial, gender, or political bias.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)
Bias is a highly subjective matter, varying significantly across different geographical, geopolitical, and geosocial environments. For example, language or expressions considered neutral in one culture may carry different connotations in another. (This is also why few-shot evaluation doesn’t work well for bias.)
A potential solution would be to fine-tune a custom LLM for evaluation or provide extremely clear rubrics for in-context learning, and for this reason, I believe bias is the hardest metric of all to implement.
Use Case Specific Metrics
Summarization
I actually covered the summarization metric in depth in one of my previous articles, so I would highly recommend to give it a good read (and I promise its much shorter than this article).
In summary (no pun intended), all good summaries:
- Is factually aligned with the original text.
- Includes important information from the original text.
Using QAG, we can calculate both factual alignment and inclusion scores to compute a final summarization score. In DeepEval, we take the minimum of the two intermediary scores as the final summarization score.
from deepeval.metrics import SummarizationMetric
from deepeval.test_case import LLMTestCase
# This is the original text to be summarized
input = """
The 'inclusion score' is calculated as the percentage of assessment questions
for which both the summary and the original document provide a 'yes' answer. This
method ensures that the summary not only includes key information from the original
text but also accurately represents it. A higher inclusion score indicates a
more comprehensive and faithful summary, signifying that the summary effectively
encapsulates the crucial points and details from the original content.
"""
# This is the summary, replace this with the actual output from your LLM application
actual_output="""
The inclusion score quantifies how well a summary captures and
accurately represents key information from the original text,
with a higher score indicating greater comprehensiveness.
"""
test_case = LLMTestCase(input=input, actual_output=actual_output)
metric = SummarizationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
Admittedly, I haven’t done the summarization metric enough justice because I don’t want to make this article longer than it already is. But for those interested, I would highly recommend reading this article to learn more about building your own summarization metric using QAG.
Conclusion
Congratulations for making to the end! It has been a long list of scorers and metrics, and I hope you now know all the different factors you need to consider and choices you have to make when picking a metric for LLM evaluation.
The main objective of an LLM evaluation metric is to quantify the performance of your LLM (application), and to do this we have different scorers, with some better than others. For LLM evaluation, scorers that uses LLMs (G-Eval, Prometheus, SelfCheckGPT, and QAG) are most accurate due to their high reasoning capabilities, but we need to take extra pre-cautions to ensure these scores are reliable.
At the end of the day, the choice of metrics depend on your use case and implementation of your LLM application, where RAG and fine-tuning metrics are a great starting point to evaluating LLM outputs. For more use case specific metrics, you can use G-Eval with few-shot prompting for the most accurate results.
- 登录 发表评论