category
多模式Instruction Following Data
基于COCO数据集,我们与纯语言GPT-4进行了交互,共收集了158K个唯一语言图像指令跟随样本,其中对话样本58K个,详细描述样本23K个,复杂推理样本77k个。请在[HuggingFace数据集]上签出“LLaVA-Instruct-150K”。
| Data file name | File Size | Sample Size |
|---|---|---|
| conversation_58k.json | 126 MB | 58K |
| detail_23k.json | 20.5 MB | 23K |
| complex_reasoning_77k.json | 79.6 MB | 77K |
For each subset, we visualize the root noun-verb pairs for the instruction and response. For each chart, please click the link for the interactive page to check out the noun-verb pairs whose frequency is higher the given number.
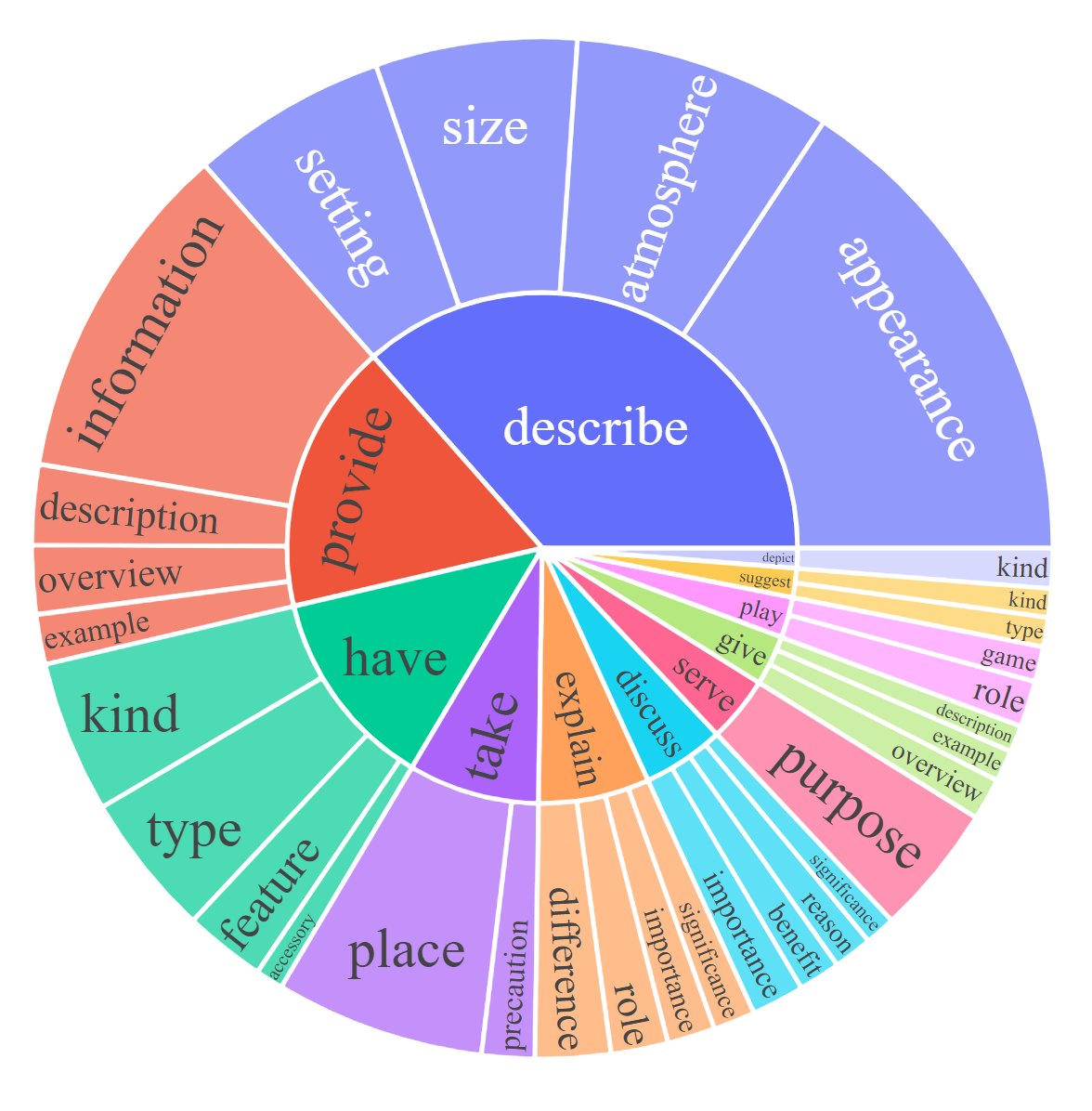
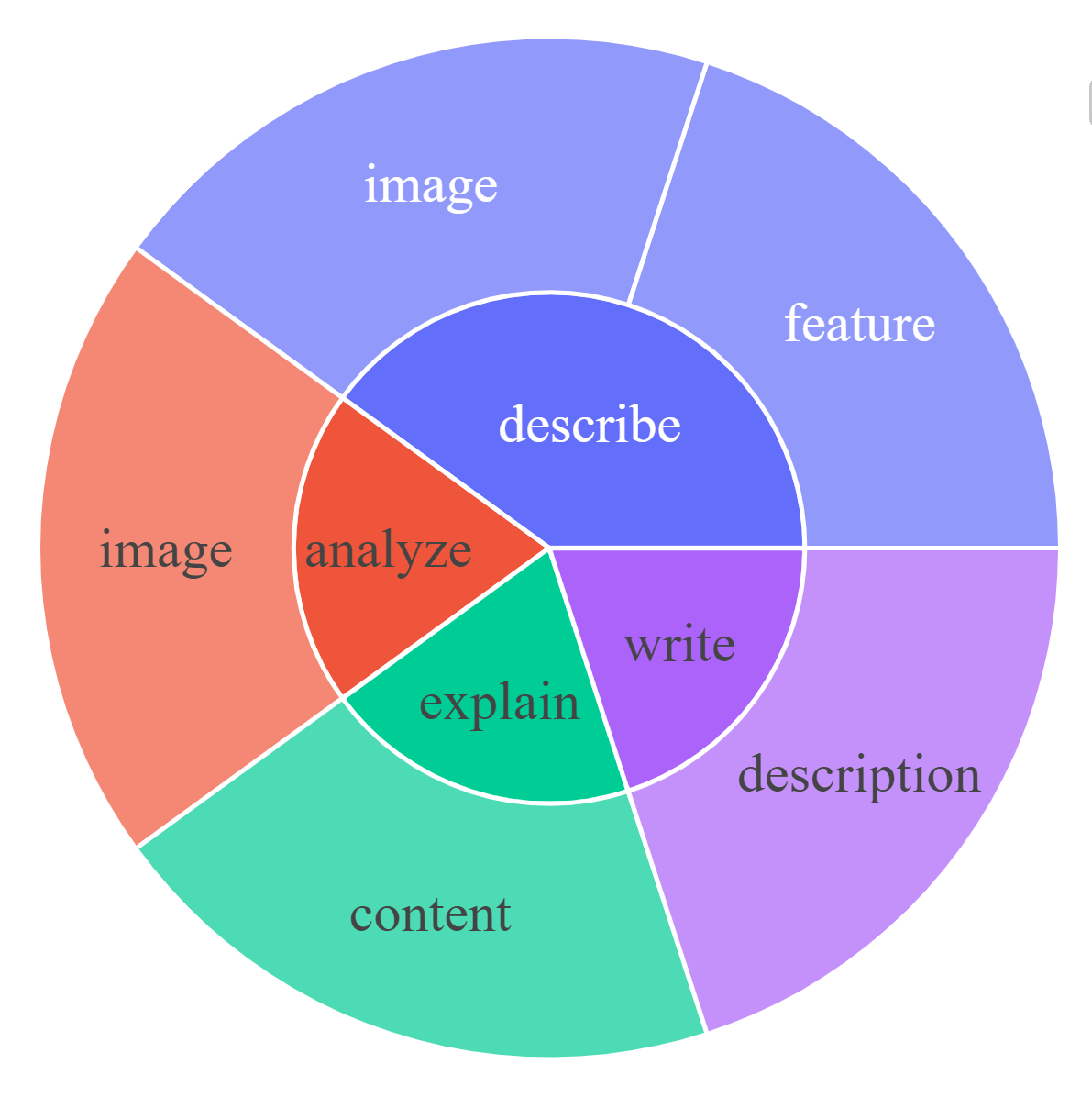
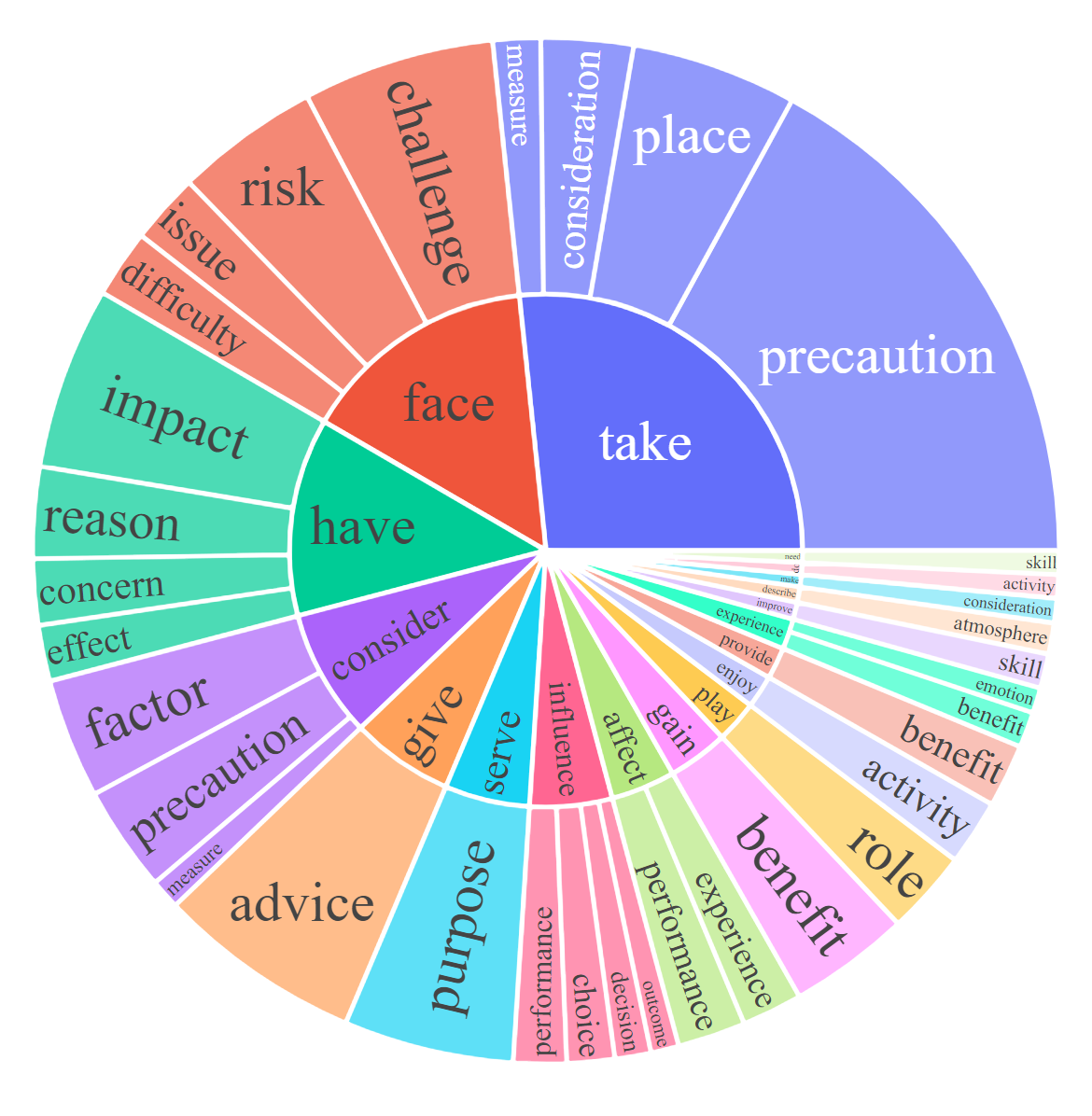
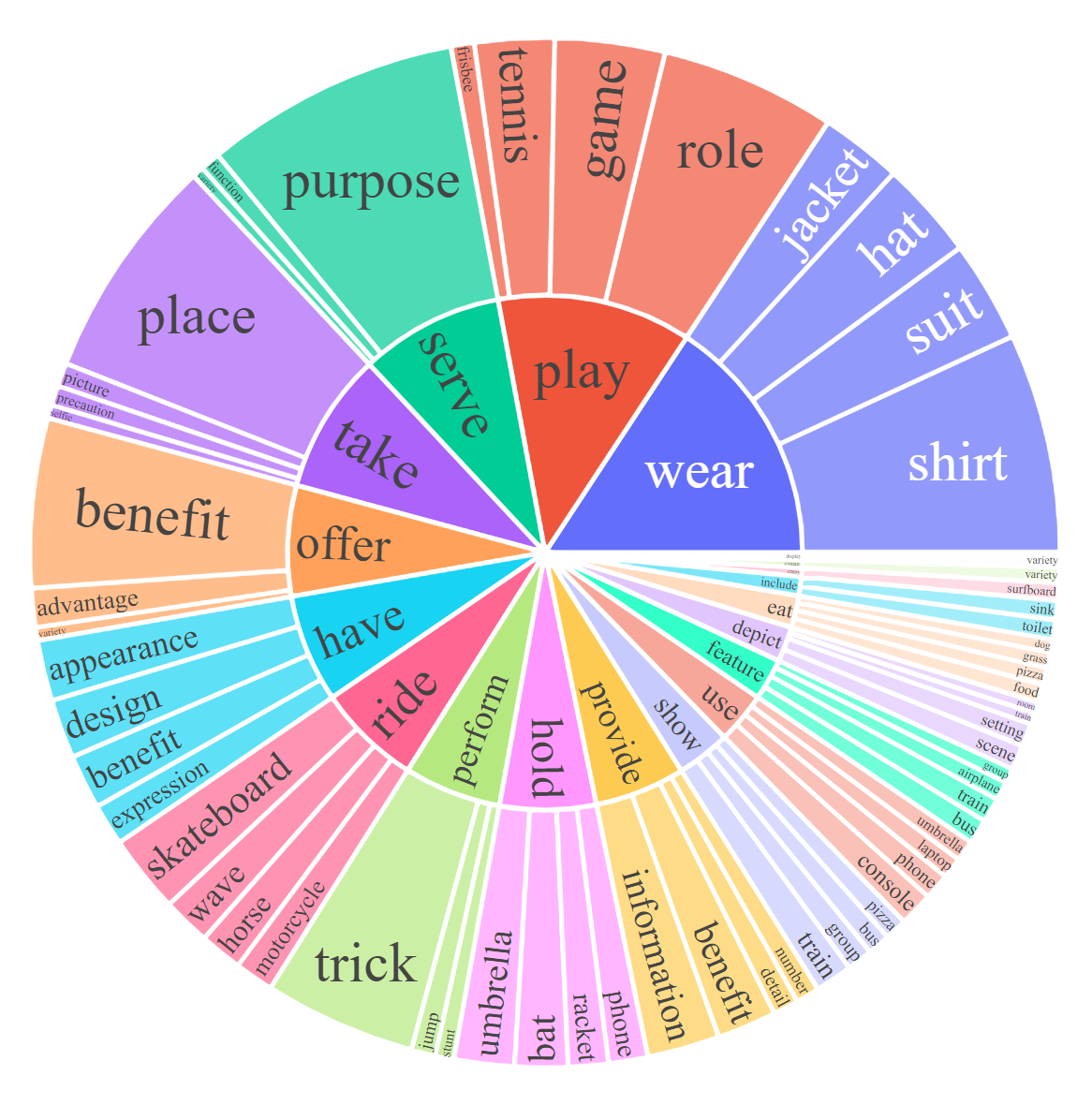

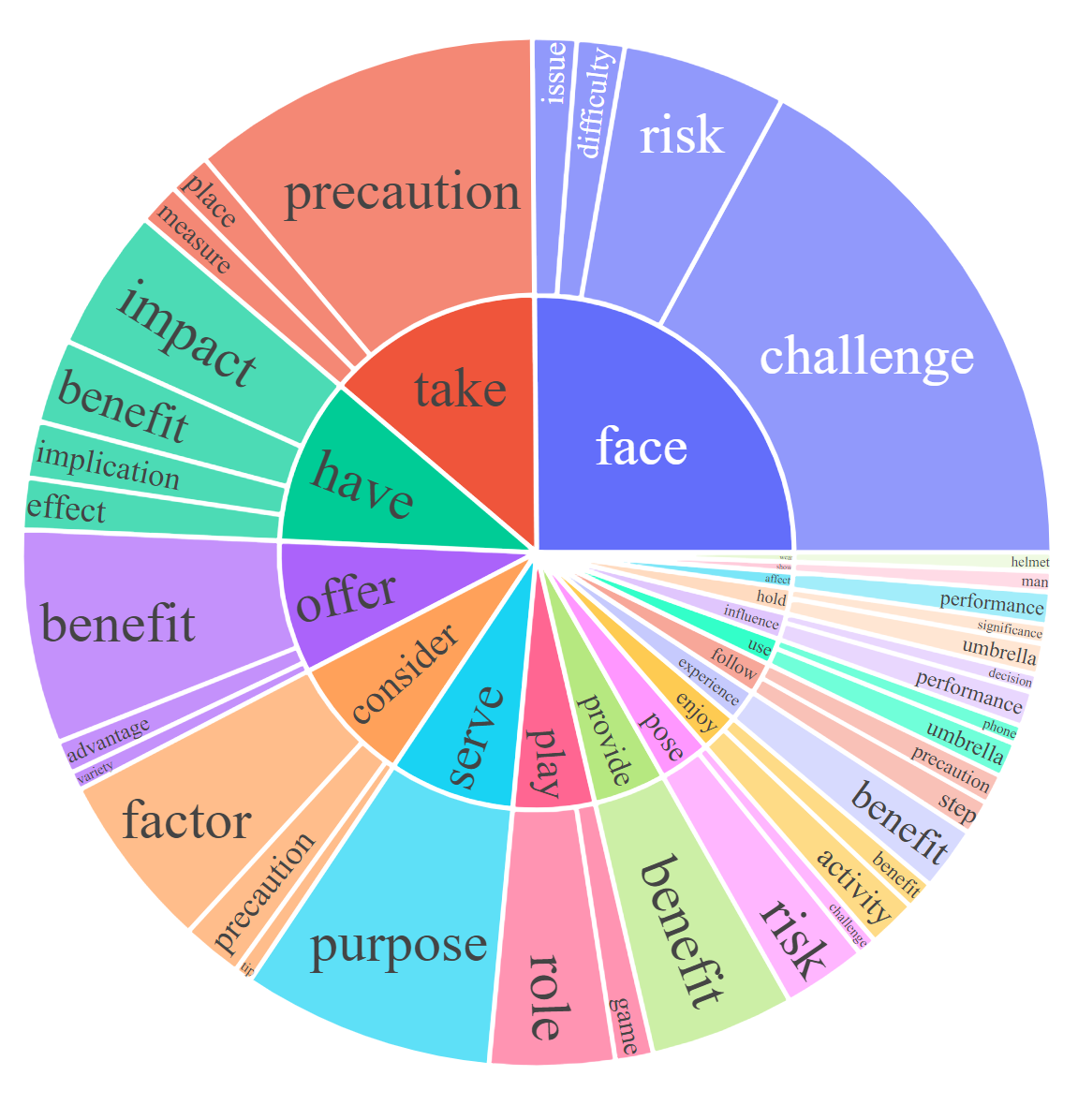
Response: Complex Reasoning [0, 20, 50]
LLaVA:大型语言和视觉助理
LLaVa使用简单的投影矩阵连接预先训练的CLIP ViT-L/14视觉编码器和大型语言模型Vicuna。我们考虑两阶段的指令调整过程:
- 阶段1:特征对齐的预训练。基于CC3M的子集,仅更新投影矩阵。
- 第二阶段:端到端微调。投影矩阵和LLM都针对两种不同的使用场景进行更新:
- Visual Chat:LLaVA对我们为日常面向用户的应用程序生成的多模式指令数据进行了微调。
- LLaVA对科学领域的多模态推理数据集进行了微调。

 Performance
Performance
 Visual Chat: Towards building multimodal GPT-4 level chatbot
Visual Chat: Towards building multimodal GPT-4 level chatbot
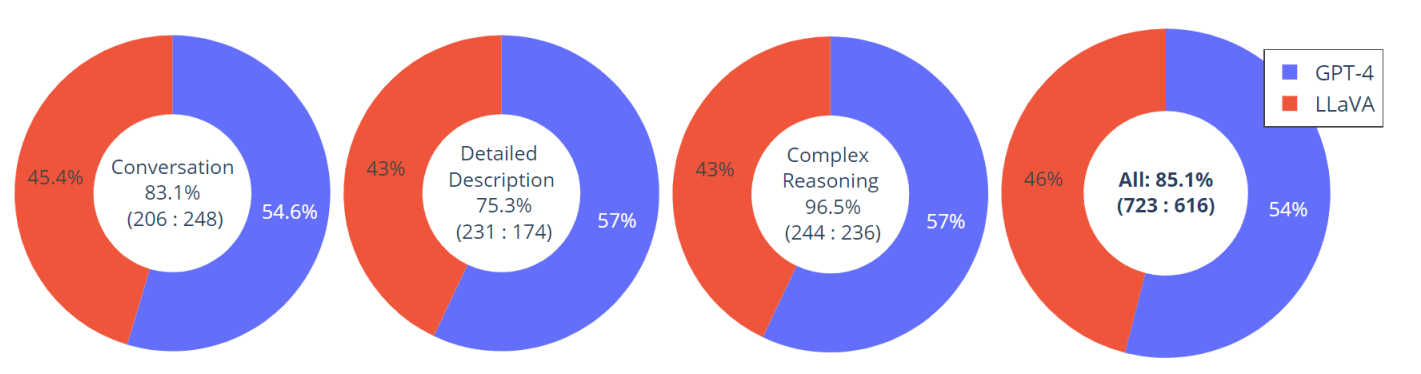
构建了一个包含30幅看不见的图像的评估数据集:每张图像都与三种类型的指令相关联:对话、详细描述和复杂推理。这导致了90条新的语言图像指令,我们在这些指令上测试LLaVA和GPT-4,并使用GPT-4对它们的反应进行评分,从1分到10分。报告每种类型的总得分和相对得分。总体而言,与GPT-4相比,LLaVA获得了85.1%的相对分数,这表明所提出的自我指导方法在多模式环境中的有效性
科学QA:LLaVA与GPT-4协同作用的新型SoTA
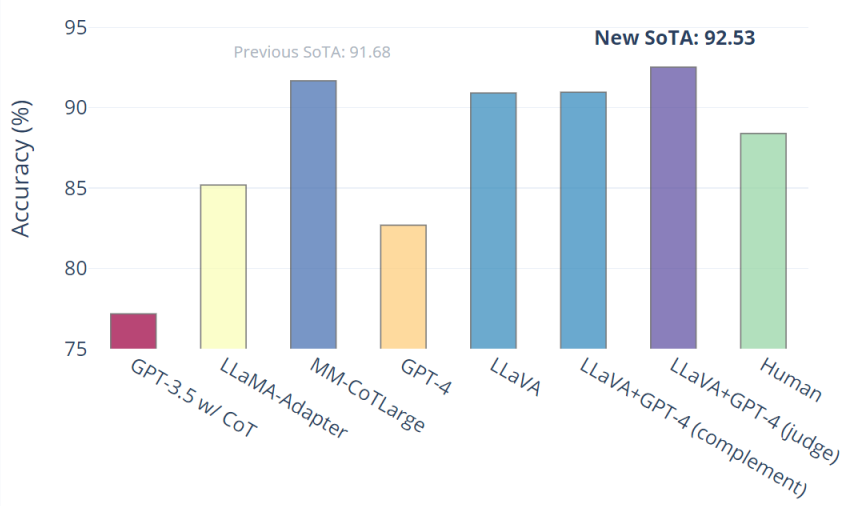
LLaVA单独达到90.92%。我们使用纯文本GPT-4作为判断,根据其之前的答案和LLaVA答案来预测最终答案。这种“GPT-4作为判断”方案产生了92.53%的新SOTA。
视觉教学跟随示例
OpenAI GPT-4技术报告中两个例子的可视化推理

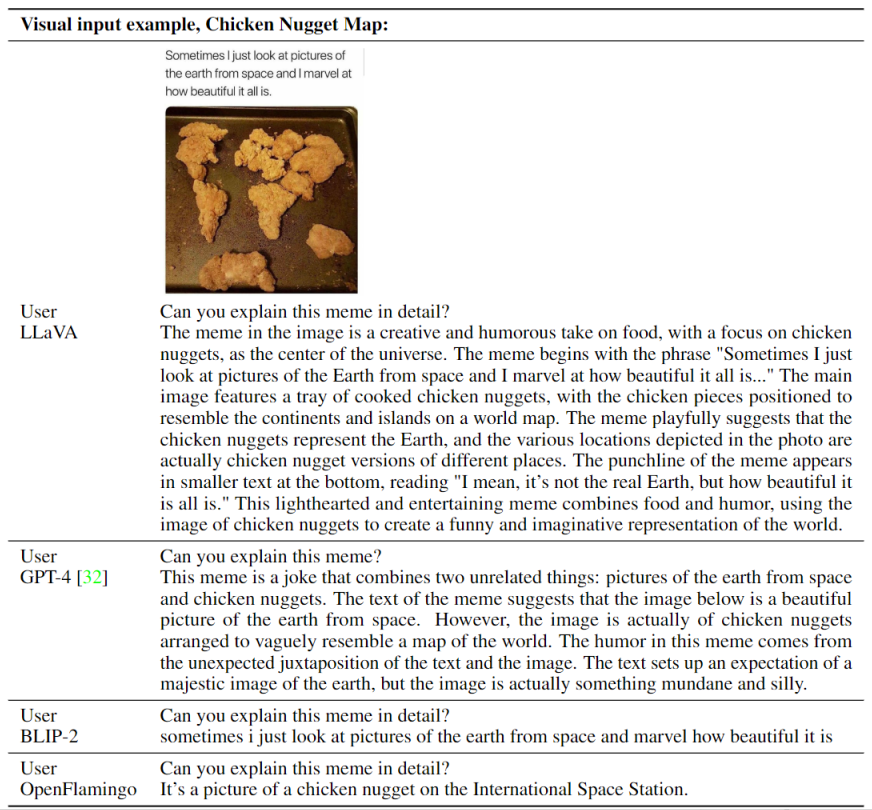
Optical character recognition (OCR)
![]()
- 登录 发表评论