category
在这本烹饪书中,我们将研究一个Text2SQL用例,在这个用例中,我们从头开始,没有一个漂亮干净的问题、SQL查询或预期响应数据集。尽管eval数据集在学术环境中很受欢迎,但在现实世界中往往不可用。在这种情况下,我们将使用一些简单的手写问题和LLM来构建一个数据集,以基于SQL数据集生成样本。
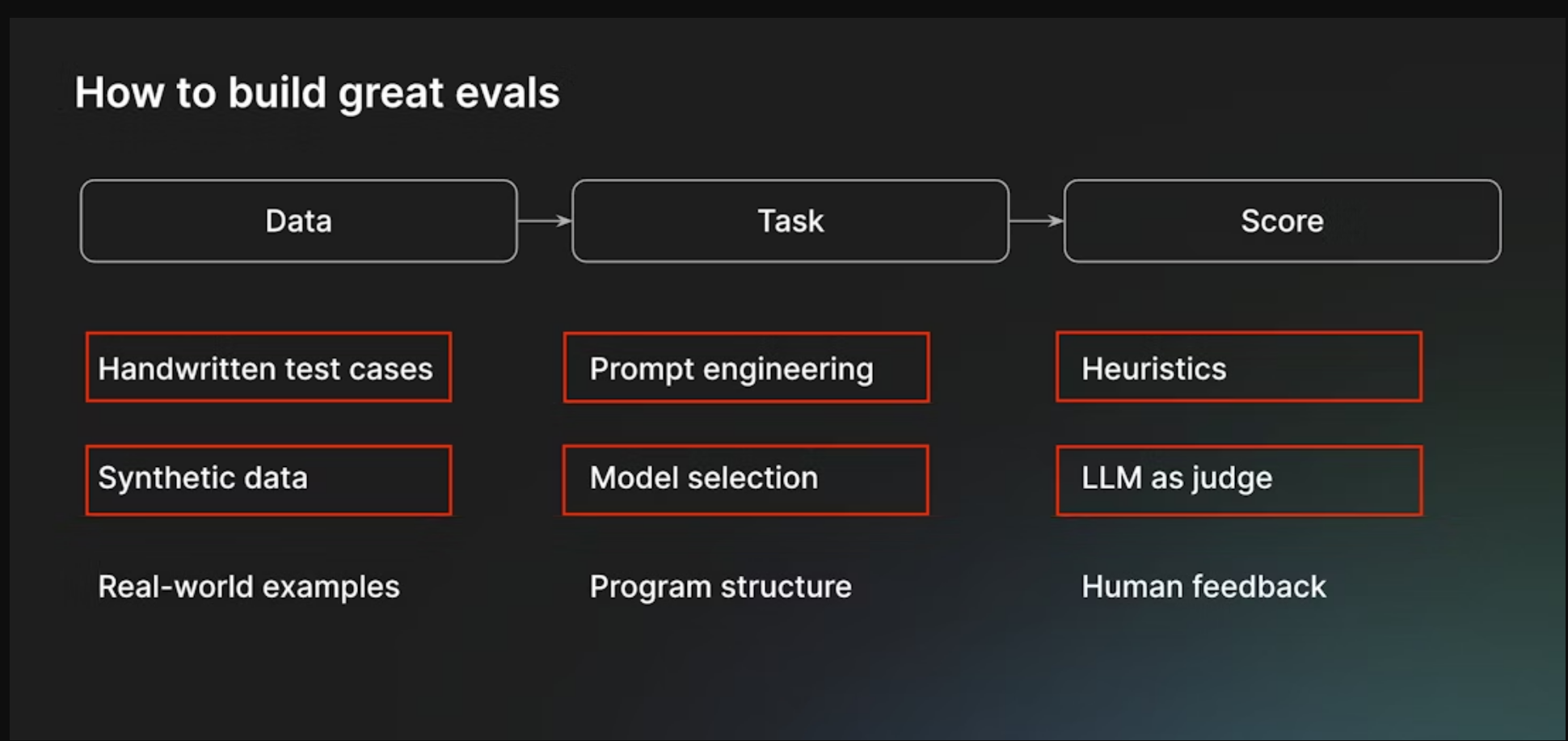
在此过程中,我们将介绍eval过程的以下组成部分:
在开始之前,请确保您拥有Braintrust帐户。如果你没有,请注册。
设置环境
接下来的几个命令将安装一些库,并包含text2sql应用程序的一些帮助代码。您可以在自己的工具中自由复制/粘贴/调整/重用此代码。
%pip install -U autoevals braintrust duckdb datasets openai pyarrow pydantic --quiet
正在下载数据
我们将使用一个NBA数据集,其中包括2014-2018年的比赛信息。让我们先下载它并四处看看。
我们将使用DuckDB作为数据库,因为它很容易直接嵌入到笔记本中。
Prototyping text2sql
现在我们已经准备好了基本数据,让我们实现text2sql逻辑。一开始不要过于复杂。我们以后总是可以改进它的实施!
Awesome, let’s try running the query!
初始评估Eval()由三部分组成——数据、任务和分数。我们将从数据开始。
创建初始数据集
让我们手写几个例子来引导数据集。尝试手写问题和SQL查询/输出将是一件非常痛苦的事情,而且可能很脆弱。相反,我们只写一些问题,并尝试在没有预期输出的情况下评估输出.
Task function
现在让我们编写一个任务函数。该函数应接收输入(问题)并返回输出(SQL查询和结果)。
分数
目前,我们无法获得太多分数,但我们至少可以检查SQL查询是否有效。如果我们生成了一个无效的查询,错误字段将不为空。
Eval
就是这样!现在,让我们把这些东西插在一起,进行一次评估。
Ok! It looks like 3/5 of our queries are valid. Let’s take a closer look in the Braintrust UI.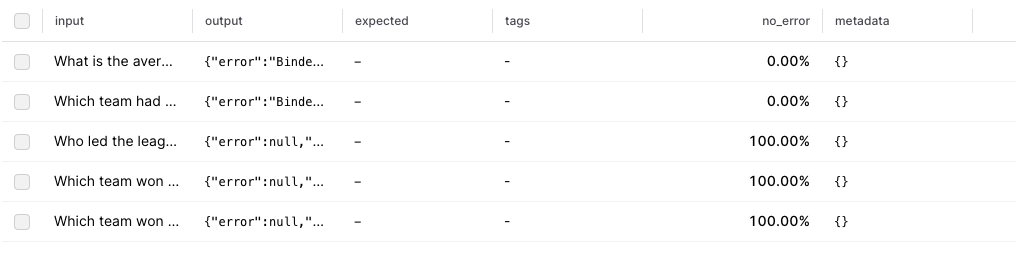
解读结果
现在我们运行了初始eval,看起来其中两个结果有效,两个产生SQL错误,一个不正确。为了最好地利用这些结果:
让我们将好的数据捕获到数据集中。由于我们的eval管道做了生成引用查询和结果的艰苦工作,我们现在可以保存这些查询和结果,并确保我们未来所做的更改不会使结果倒退。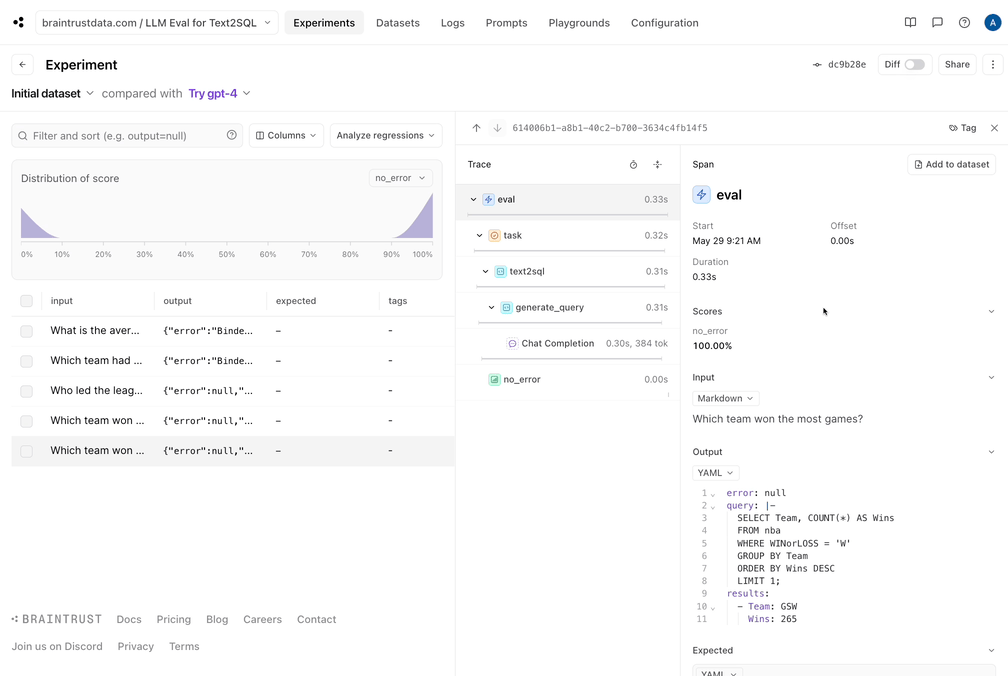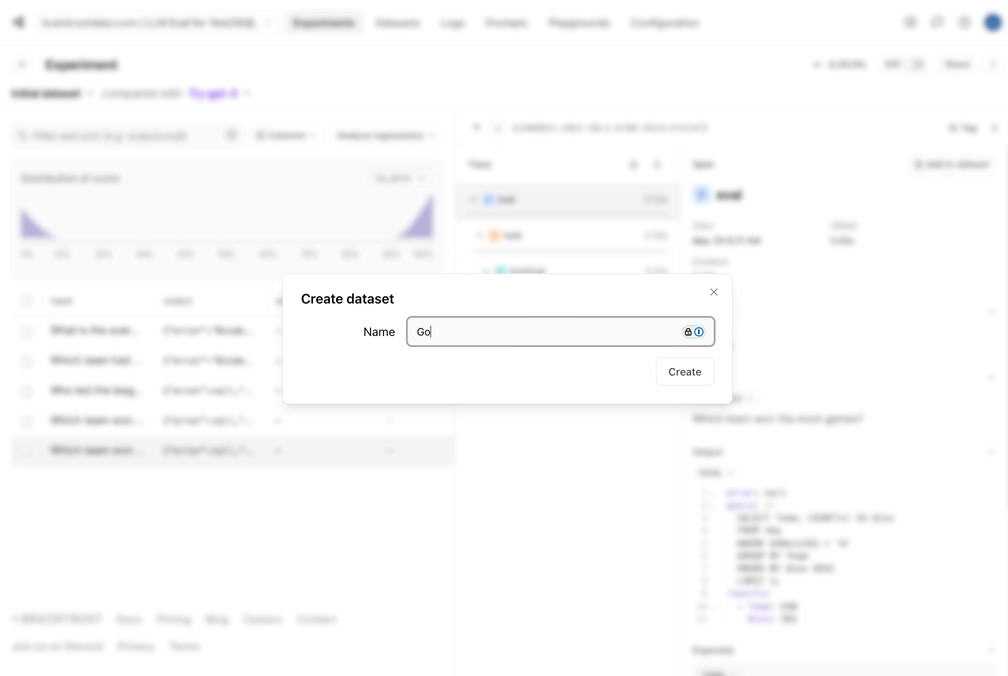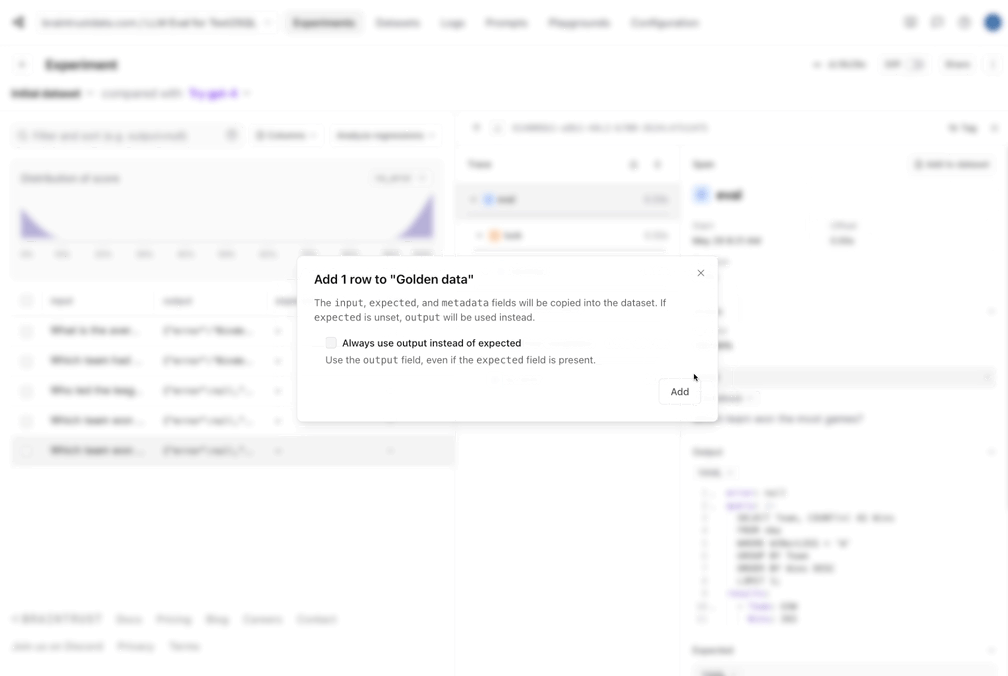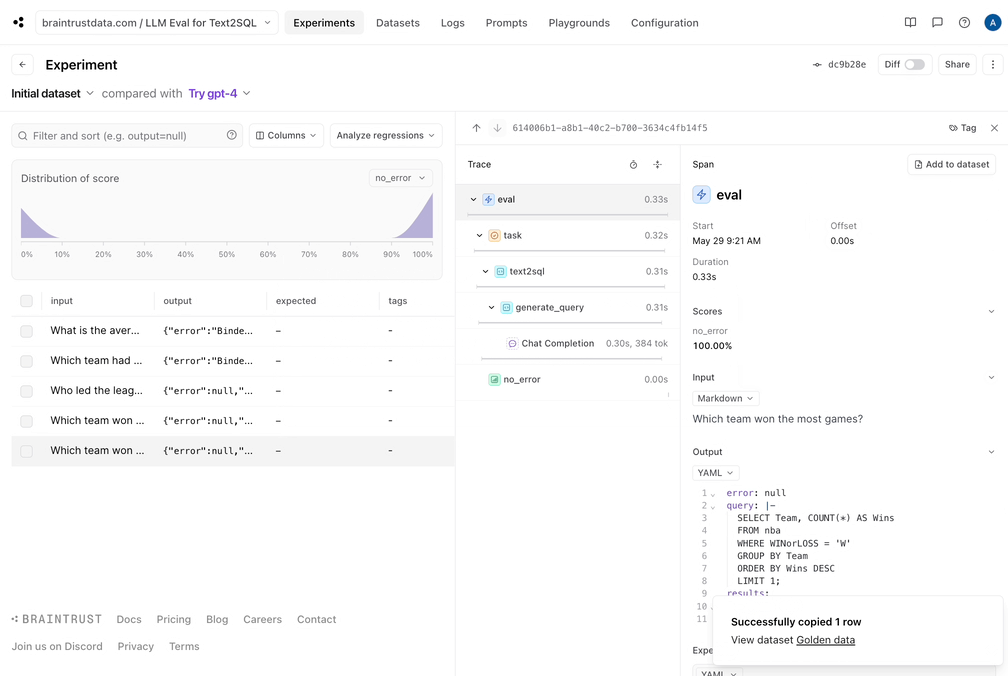
- The incorrect query didn’t seem to get the date format correct. That would probably be improved by showing a sample of the data to the model.

- There are two binder errors, which may also have to do with not understanding the data format.

Updating the eval
Let’s start by reworking our data 函数用于提取我们存储在Braintrust中的黄金数据,并用手写问题对其进行扩展。由于可能存在一些重叠,我们会自动排除数据集中已经存在的任何问题。
Now, let’s tweak the prompt to include a sample of each row.
看起来好多了!最后,让我们添加一个评分函数,将结果(如果存在)与预期结果进行比较。
Great. Let’s plug these pieces together and run an eval!
Amazing. It looks like we removed one of the errors, and got a result for the incorrect query.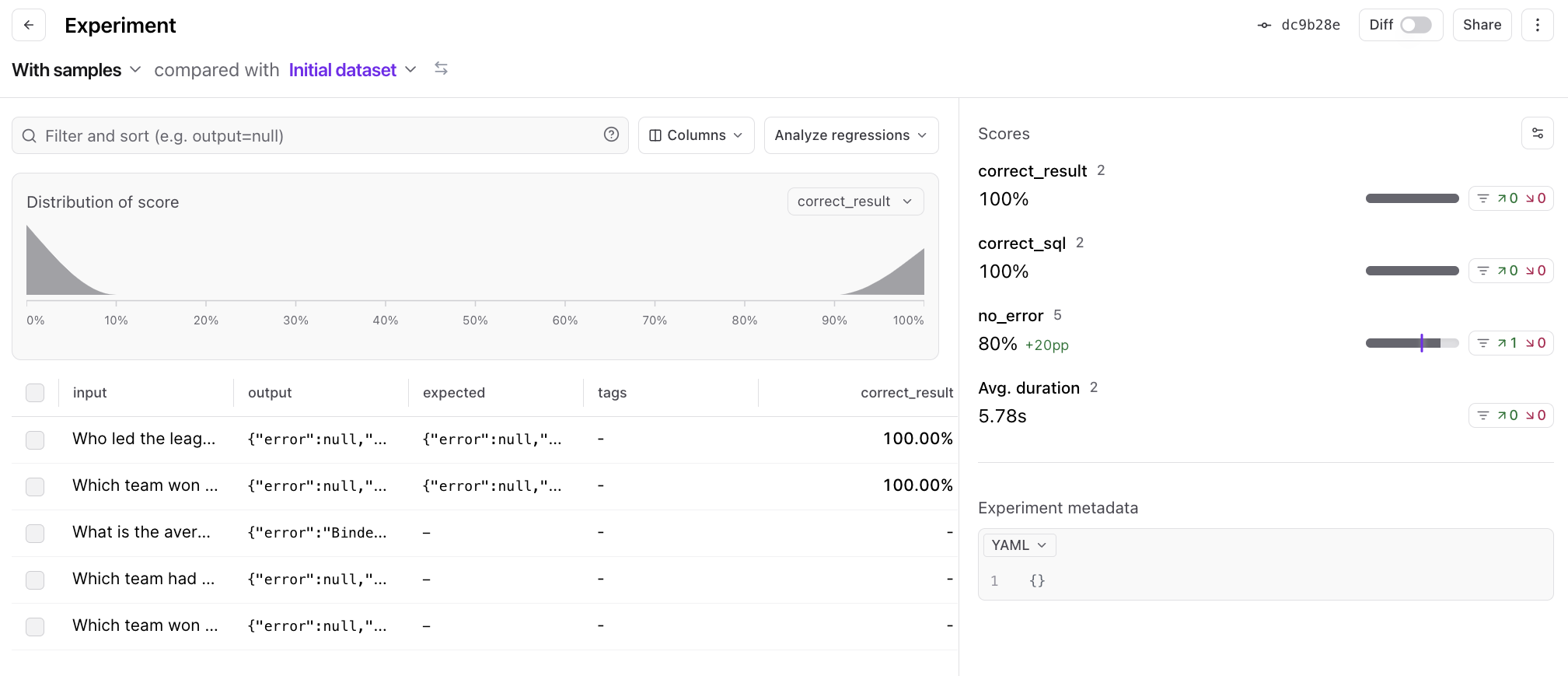
生成更多数据
现在我们已经有了一个基本的流程,让我们生成一些数据。我们将使用数据集本身来生成预期的查询,并使用一个模型来描述查询。这是一种比让它生成查询更稳健的方法,因为我们希望模型比从头开始生成查询更准确地描述查询。
Awesome, let’s update our dataset with the new data.
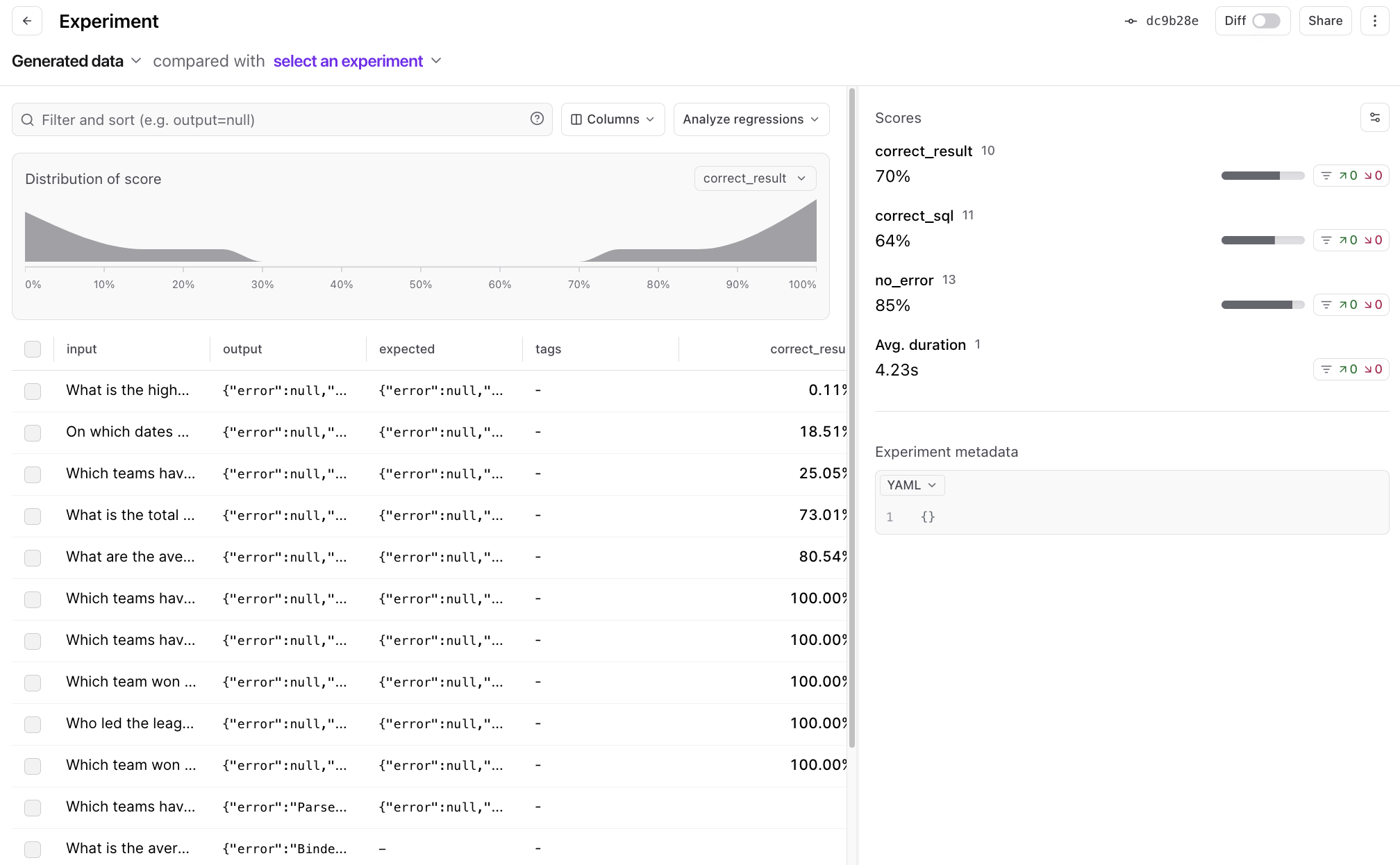
太神了!现在我们有一个丰富的数据集可以使用,也有一些故障需要调试。从这里开始,你可以尝试调查一些生成的数据是否需要改进,或者尝试调整提示以提高准确性,或者甚至可能是更冒险的事情,比如将错误反馈给模型,让它迭代出更好的查询。最重要的是,我们有一个很好的工作流程来迭代应用程序和数据集。
Trying GPT-4
Just for fun, let’s wrap things up by trying out GPT-4. All we need to do is switch the model name, and run our Eval() function again.
有趣。看起来那不是灌篮。每个分数都有一些回归:Braintrust可以轻松过滤回归,并查看并排差异: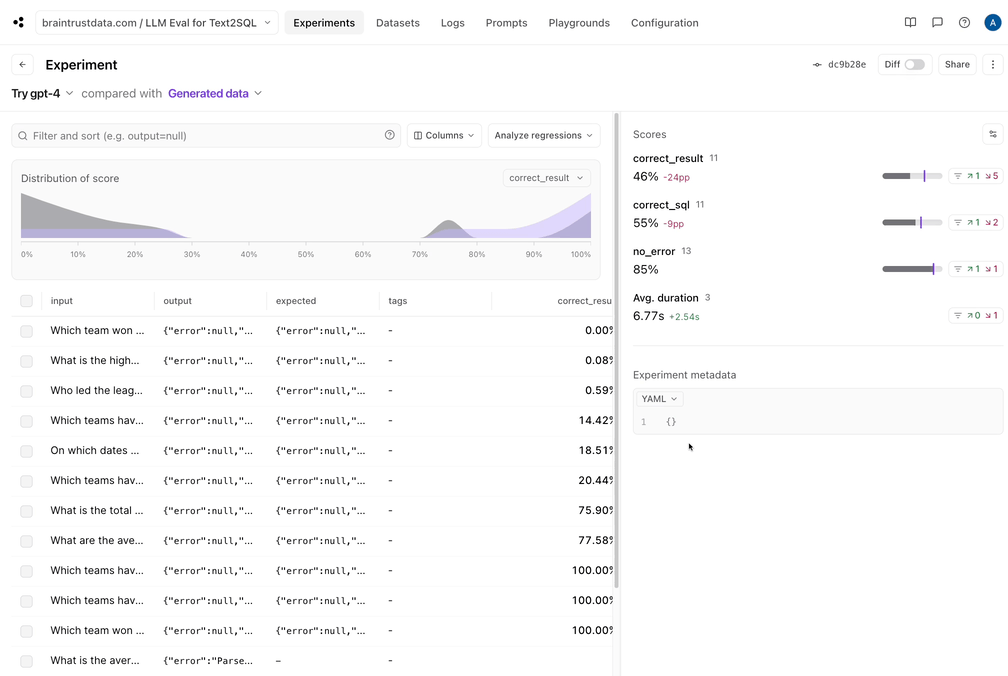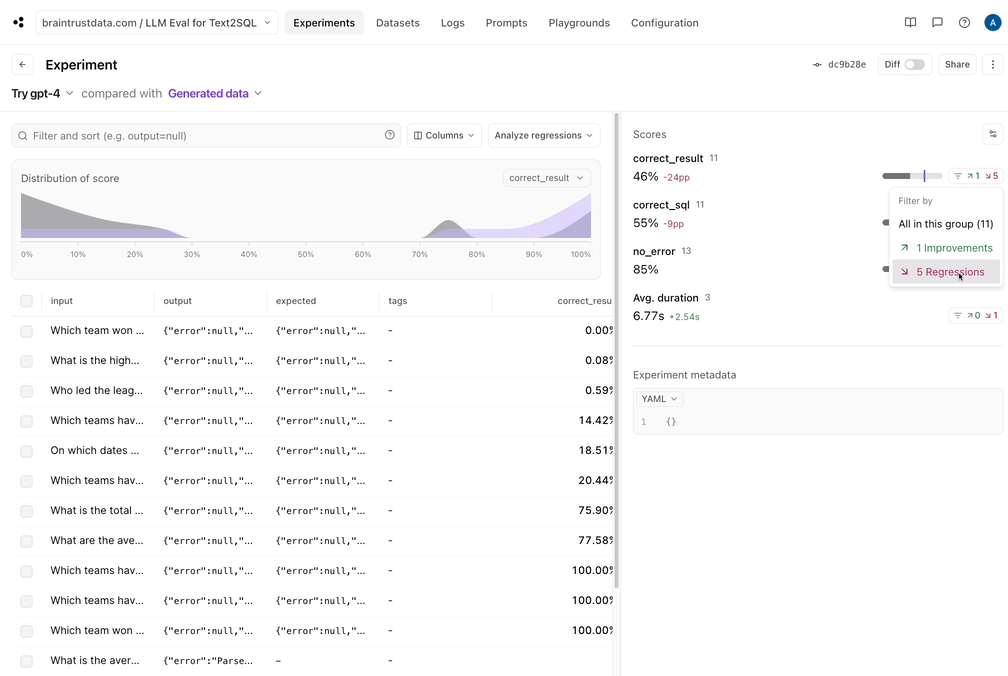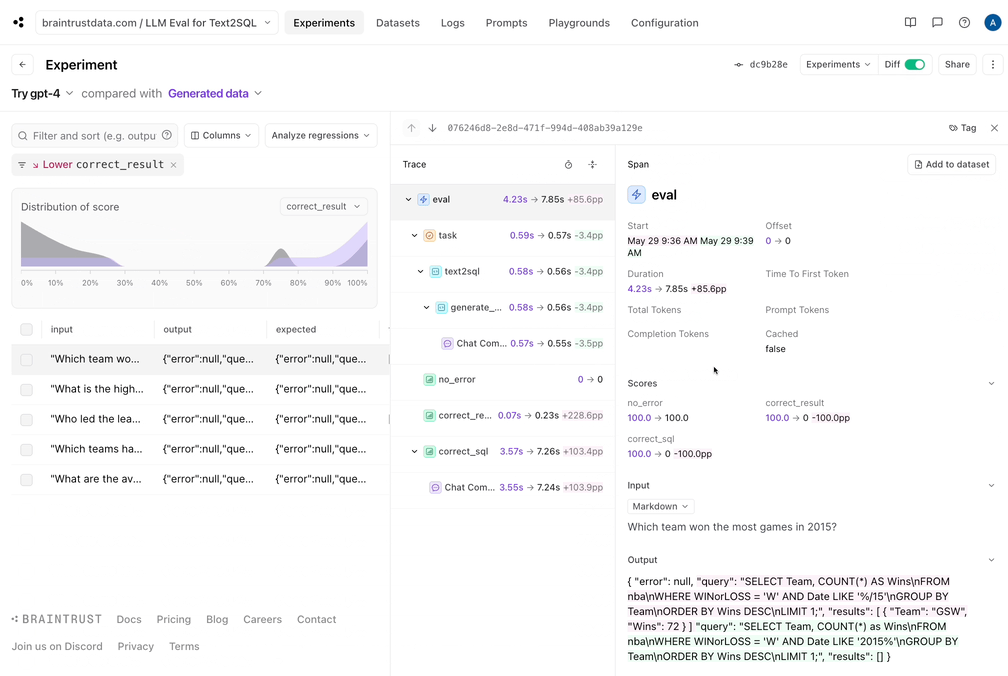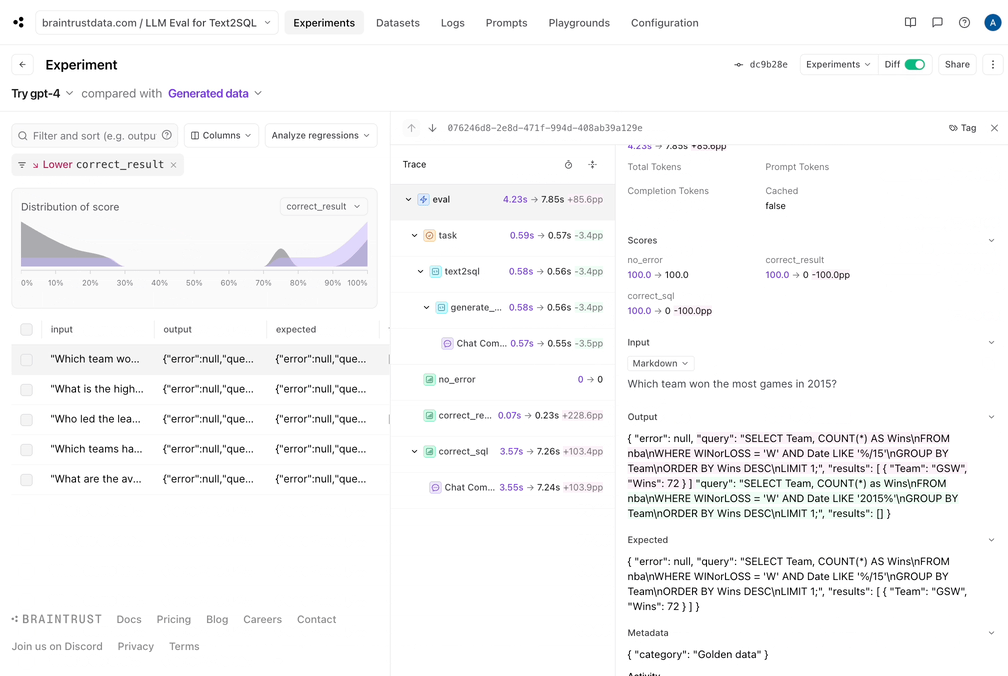
结论
在这本烹饪书中,我们介绍了为text2sql应用程序构建数据集的过程。我们从几个手写示例开始,并使用LLM在数据集上迭代以生成更多示例。我们使用eval框架来跟踪我们的进度,并对模型和数据集进行迭代以改进结果。最后,我们尝试了一个更强大的模型,看看它是否可以改善结果。快乐撤离!
- 登录 发表评论